Experimental Results
We’re always doing experiments. Right now we’re probably doing more formal experiments than normal, but whenever you’re doing something new it could be considered an experiment. Depending on your knowledge and experience, it might be one with a much higher expectation of success than a traditional experiment, but writing code is just an experiment to validate the hypothesis that is the design.
Coding, like all experiments, will have a result. Since you’re writing the code to add value, you have a vested interest in a specific outcome. Sometimes though, the outcome isn’t what you hoped for. So how do you move forward at that point? One thing is for sure, don’t keep digging.
But even before that, what do you call that result. Remember, naming things is one of the hard problems, and that doesn’t just apply to methods and variables. It’s not a mistake or failure. Assuming you were thoughtful in your choices, they might have been incorrect, but they weren’t a mistake. While the code might not work as intended, the experiment isn’t a failure.
One way to think about is is with this picture:
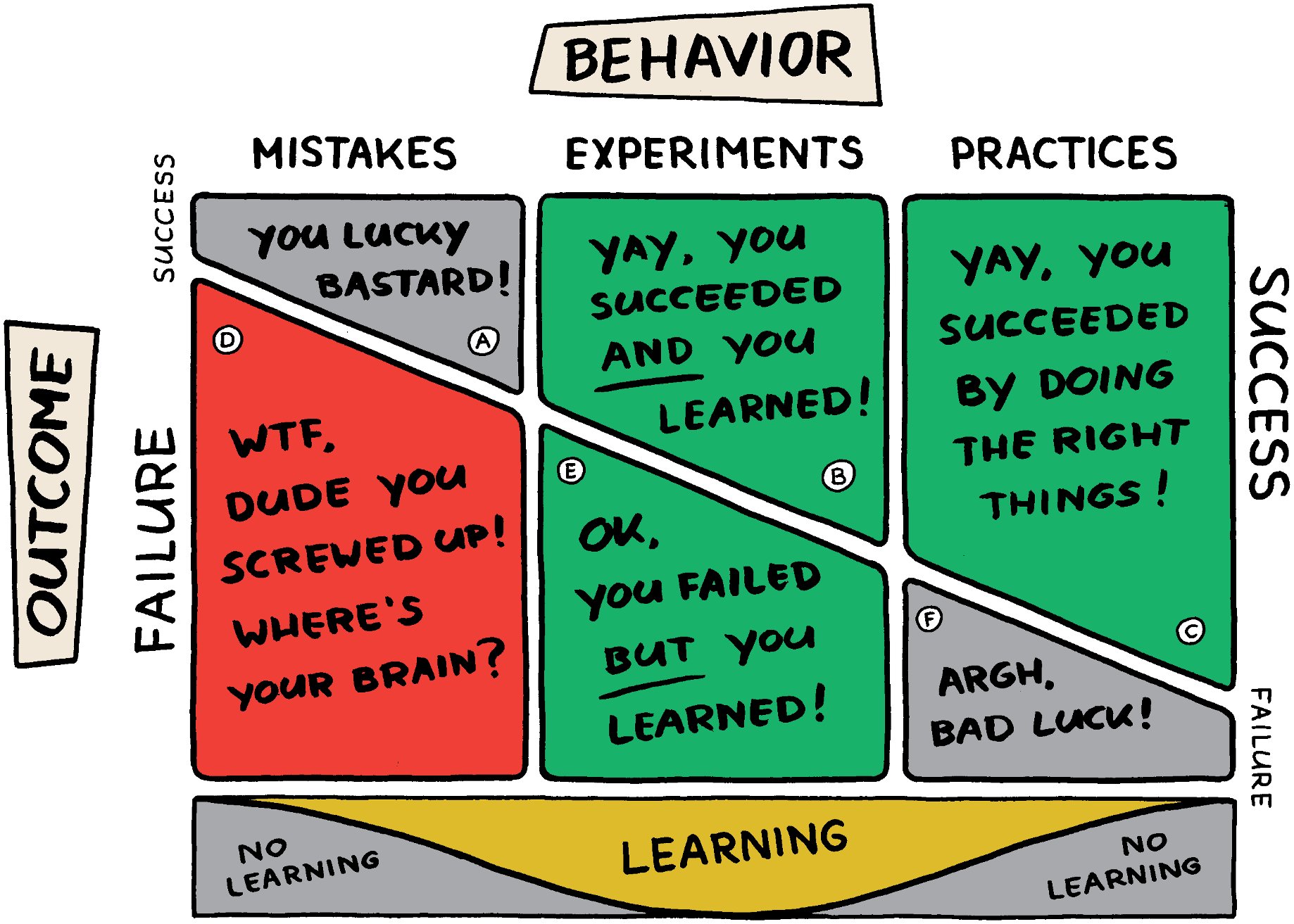
And in this case, experiments, regardless of the outcome, have the most learning. If you take the time to learn from it.
So what do you call it when an experiment has an unexpected outcome?
