Home Ownership and Software Updates
Seen on Bluesky
Homeownership is a lifelong commitment to discovering what it takes to modernize a legacy system and the lengths to which you will go and compromises you will make in doing so.
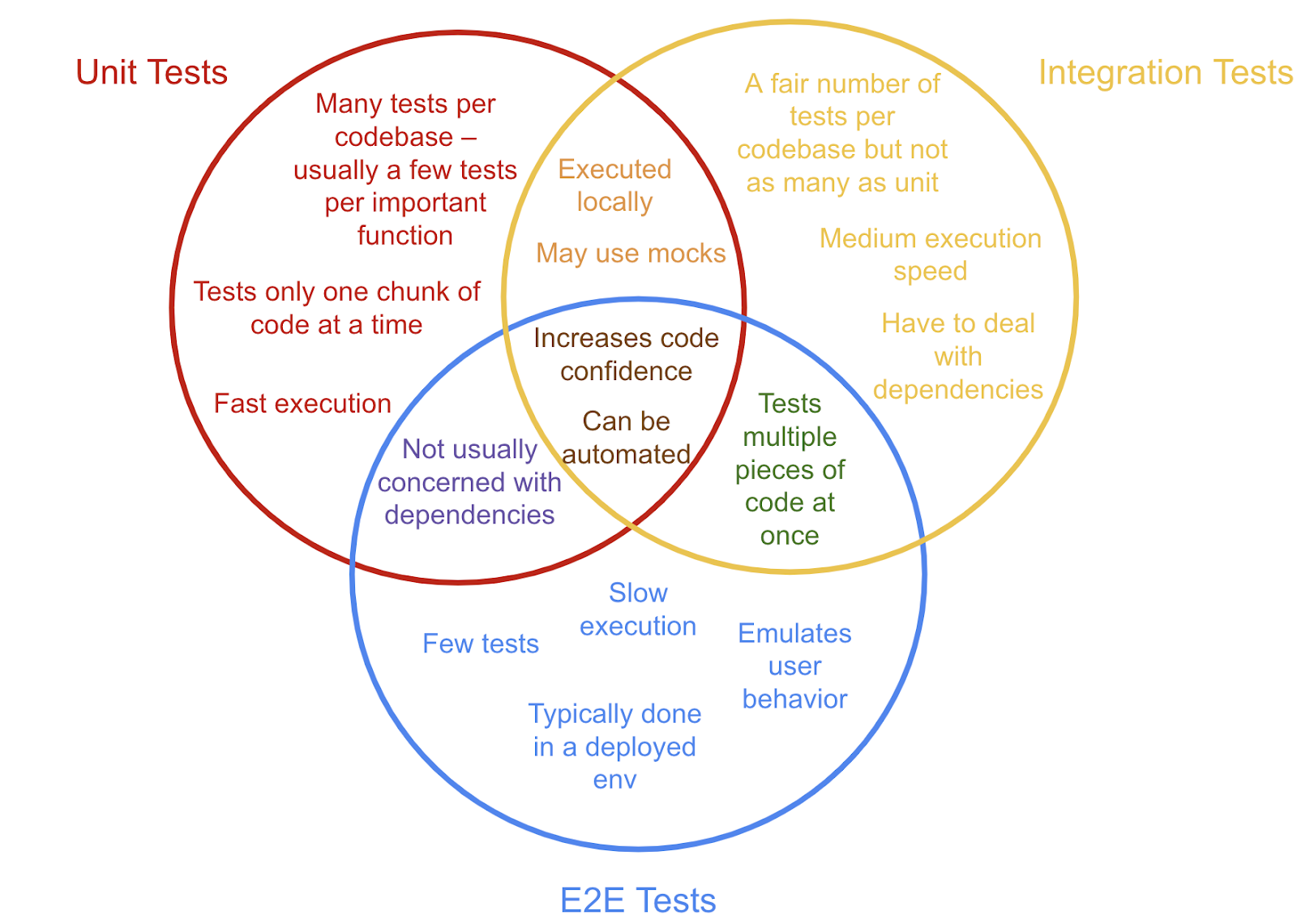
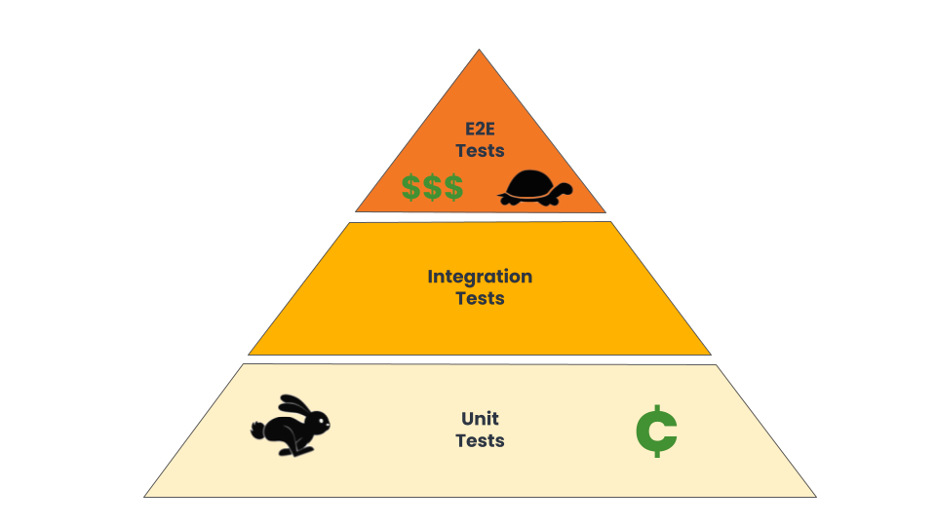
It’s often been said that software development is like home construction. You have a site, some requirements, a plan, you start to build, then you adjust as needed. There’s some truth to that, and from far enough away, it’s accurate.
However, when you look closer the analogy falls apart. First, we’ve been building homes a lot longer than we’ve been writing programs. The number of things that are known to home builders as tacit knowledge vastly outnumbers the tacit knowledge of software developers. Most developers have built a handful of programs, or the same program many times. Especially developers that work on their own or in a small company. On the other hand, your typical home building company has a much larger legacy behind them. They made those mistakes before. And the industry made some of them so long ago that the fix is documents. As building codes.
Which is the second big difference. Home building is a regulated industry. Even if you’re building everything yourself, there aren’t many places left where you don’t have to follow the same rules and regulations as every other builder, and, your work will be inspected by a third party when it’s done. There aren’t many software projects where the local government software inspector comes by and makes sure you don’t have any dangling pointers, missing null checks, or all the known security patches. That almost certainly happened to your house though. At multiple times during the build, the inspector came out and checked the plumbing, the electrical, the framing, the layout of the stairs, and even how many electric outlets you have.
Those differences aside, one way that homes and software are similar is updates. At some point, potentially long after the original builder and owner are no longer involved, the current owner is going to reach out to a new builder and say “Can you change X because I want to do Y”. And the builder is going to say yes. Then figure out how to do it. Or at least try to, And find that there’s a pipe right where the new owner wants a doorway. Or the walls just aren’t strong enough to support a second floor. Or someone secretly added another set of outlets to an existing circuit, and plugging in one more phone charge blows the main breaker for the entire house.
So the builder figures out how to make things work. They convince the new owner that want the door four feet to the left, or they add a parallel electric system to the house, or the build a second story on stilts so it’s really a new house carefully place just above the current house, so the stairways line up, but in fact they’re completely separate.1 Then it happens a few months later, and not only does the builder have to deal with the original build, but they also must deal with the compromises and issues that came from the first change. When you do a home remodel, you not only have to design in the things you want, you have to design in the choices of the original builder (and any change between now and then).
With software it’s kind of the same thing. Especially legacy software. Decisions were made. For probably good reasons at the time. To deal with a known requirement. As with Chesterton’s Fence, unless you know exactly why something was done and that it’s no longer needed, you shouldn’t change it. So when you have to add a new feature to a piece of software, the first thing you need to do is make sure you haven’t broken any of your current users (Hyrum’s Law).
That means each time you need to change something, whether it’s a building or software, unless you work very hard, and do things that are not directly related to the thing you’re trying to enable, you make it harder to make the next change.
So THINK before you make that change. Think about what you’re trying to do. Think about how you can do it without impacting other users. And especially, think about future developers and what they’ll need to do when they have to make yet another change.

-
Back in Uber’s original headquarters there was a desire to have a stairway between the 4th and 5th floors in the middle of the common area, but the building owners didn’t allow it. In true Uber fashion, the interior design team was not deterred. Instead of giving up, they hung a spiral staircase from the deck between the 4th and 5th floors and had it go down to almost (but not quite) touch the deck of the fourth floor. Technically it met the rules. The 4th and 5th floors were not connected. It was just “Hanging Art”. Yet somehow, people could easily walk between the common areas of the two floors. But I pity the next owner of that space who just wants their floors to be floors. ↩︎