One Thing At A Time
Doing one thing and doing it well is The Unix Way. As I said in that article, tools should do one thing and do it well. If you need to do two things with two tools then connect them with a data pipe. It’s a great tenet for tools and applies to any number of systems that I’ve worked on. From text extraction to image processing to 3D model generation to an entire micro-service network.
It’s a great tenet in other areas as well. It lies at the heart of an agile development processes. Do one thing and finish it. See how it works. Get some feedback. Figure out what the next thing to do is. Do that. Lather, Rinse, Repeat. Take many more much smaller steps. You know where you are. You know where you want to be. The exact path between those two (and probably the exact destination) will change as you learn along the way. Uncovering better ways of developing software by doing it.
Another place it applies is change management. How you structure your checkins, code review (CR), pull request (PR), or whatever you call them. Every commit or CR should have one logical purpose. Sometimes that means that any given CR doesn’t add customer value. Sometimes, before you make a change that adds value you need to make a change (or multiple changes) that [makes the change you need to make easier)(/posts/2020/10/27/). And that’s OK. Because just like you should code for the maintainer, you should make CRs for the reviewer.
The question is, why is this important? After all, isn’t it faster to have one change, one big optimal step, that just works? In theory that might be the case. In practice it isn’t for, multiple reasons. Most importantly, ensuring that one big step ends up in the right place is probably impossible. We don’t know where that place is exactly, so there’s no way we can be sure we’ll hit it.
There’s another reason. A reason that has to do with combinatorics. Let’s say you have two changes you’re making. Let’s make it really simple by saying that the change either works or it doesn’t. Determining if it does or doesn’t is trivial. In this situation there are 4 possible outcomes. They both work, they both fail, or one works and the other fails. In this sitation. 75% of the possible outcomes are failures. Then. after you determine if the experiment is a failure you need to figure out which of the three possible failures it was. Then you need to fix it. The more things you try at once, the worse it gets. With 3 changes 88% of the outcomes are failures. Only the top path, with all results Heads (success) is a successful attempt.
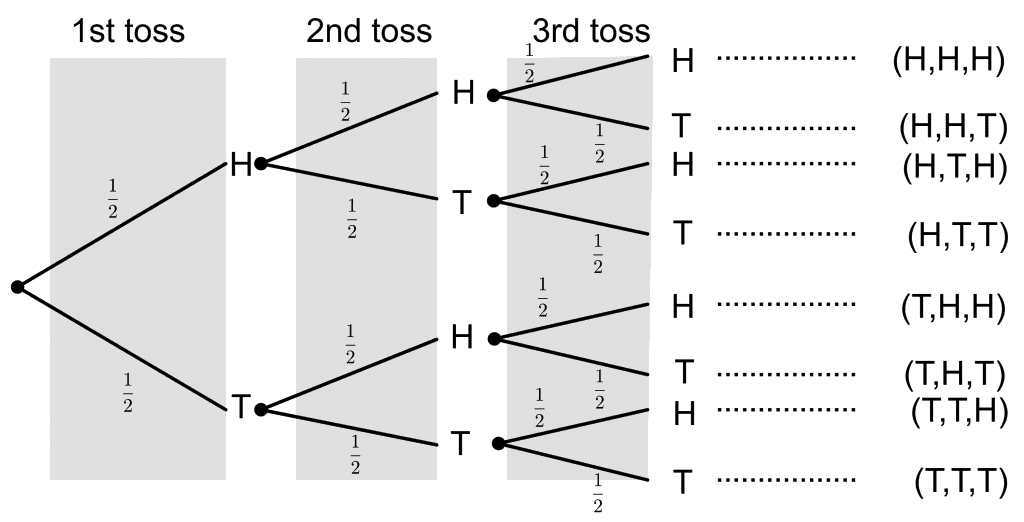
With 4 changes 94% of the possible outcomes is a failure case. Any savings you get by taking that big step are going to be eaten up by dealing with all of the possible failures. You might get lucky once or twice, but over the long term you’re much better of makig one change at a time.
It doesn’t matter if the changes are in a single CR to be reviewed, a data processing pipeline, a microservice network, or the architecture of something you haven’t built yet. The more you change at once, the harder it is to know if the changes made things better or worse. So take the time to decompose your changes into atomic, testable, reversable steps and then make the changes, doing one thing at a time. You’ll be happier. Your customers will be happier.
And surprisingly, you’ll move faster as well.
