Best Simple System For Now
When you’re writing code you have lots of choices. Even when working with 20-year-old legacy code, you have options. Not all of those options are equal though. Some are cheap and fast now, but may have a large cost later. Others are expensive and slow now, but might make things easier in the future. Your job as a software engineer is to choose the right one.
Which one is right? You can probably guess what my answer is. It Depends. Of course it does. It always does. Without the context, there is no up-front answer. In fact, both are usually wrong. You don’t want to choose the cheapest/fastest option, and you don’t want to the one that gives you the most options in the future.
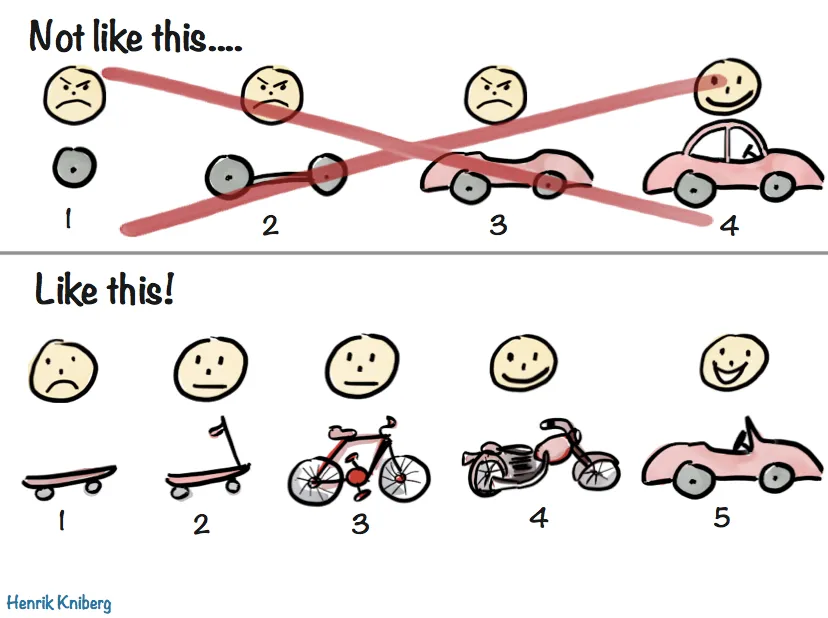
Instead, you want to choose the one that gives you a good balance of things. You want what Dan North calls the best simple system for now. It’s a very deliberate phrase. There’s a lot to think about in there.
For Now
One of the most important parts of the phrase is at the end. For Now. Given what you know at the current moment, about where you are, about what the immediate goal is, and what is between you and that solution, and what you think the long-term goals are. What can you do right now? It’s going to change. You know that. You just don’t know how it’s going to change. So you want to maintain the options, not make more decisions than you need to.
Simple
One of the best ways to maintain that optionality is to keep things simple. Simple is easy to understand. It’s easy to reason about. And most importantly, it’s easy to change. But remember, simple doesn’t mean you get to ignore things. It still needs to work. It still needs to work at the scale you’re operating at. It still needs to work when the inputs change. Or at least it needs to work well enough to tell you that it can’t work in the new situation. Remember, KISS. The simpler it is the easier to get right and the harder to get wrong.
System
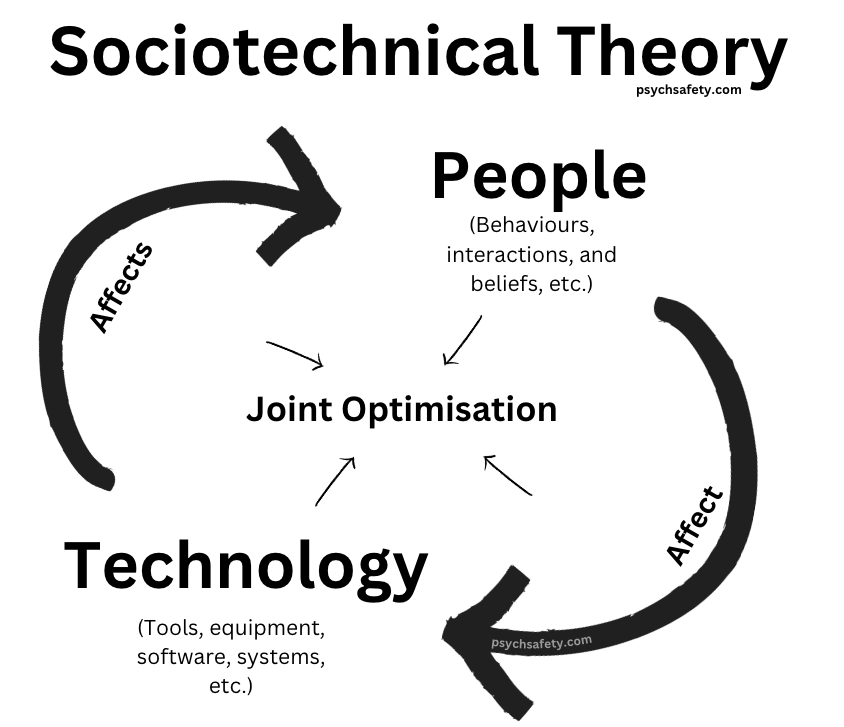
Another thing to keep in mind is that it’s a system. Even the simplest program is a system. And the important thing about systems is that the parts of a system interact with each other. Often in strange and unexpected ways. You need to remember, and minimize, emergent behavior. By keeping things simple. By remembering that you’re building a system for now.
You need to remember that systems have feedback loops. So you need to identify and understand those loops. So you can work with those loops, instead of against them. When you work against the feedback loops in a system you’re working against the entire system. If you keep trying to do that, you either change the entire system or you end up not changing anything. As John Gall said:
A complex system that works is invariably found to have evolved from a simple system that worked. A complex system designed from scratch never works and cannot be patched up to make it work. You have to start over with a working simple system.
Best
Finally, we get to best. How can you make something the best? By ensuring that what you’re building is for now. By keeping it simple. And by working with the system. If you do all of those things, you’ve got a very good chance of ending up with the best simple system for now.



{kind=link}